
Clean Architecture has revolutionized the way software development is approached, especially for beginners eager to build robust and maintainable systems. We all probably have worked on some codebase that –
- had a lot of bugs
- was painful to debug or enhance with new features
- was hard/impossible to test without things like a database or web server
- had presentation logic mixed with business logic or business logic mixed in with data access logic
- was hard for other developers to understand because it did not clearly express its intent or purpose within the application it was written for
Over time, with the knowledge of various Gang of Four patterns and a conscious effort to keep the SOLID principles running on a background thread in mind as we wrote code certainly helped mitigate the problems listed above, they didn’t eliminate them. When writing web or desktop software using MVC or MVVM, we still found some of the same old symptoms showing up in our projects. Things like business logic leaking into controllers, entity models being used all over the place for different purposes and large regions of the code that had no unit test coverage because they had some sort of direct dependency on a database or http client.
Traditional N-Tier architecture put code and functionality into layers. It’s like people standing in a line all facing the same direction. The end of the line is the presentation layer where the design and interaction is. The beginning of the line is data persistence. A person can see someone if they have dependencies on them. The person at the end of the line can see everyone in front of them – this is the presentation layer and it depends on everything.
Problem with Traditional N-Tier architecture
The problem is that the business logic layer is in the middle of the line, which is good because it doesn’t depend on the presentation layer (it can’t see it), but it still depends on data persistence and external API connections, and anything else in front of it in the line.
The idea of Clean Architecture is, instead of making it a line, we make it an onion where the center is the business logic and the layers around it take dependencies on it, but it doesn’t take dependencies on anything else. In a modern cloud environment where application might integrate with different services, data storage, etc. over time, changing those things out doesn’t require changing the business logic. These external services live behind interfaces or adapters and we can swap them out easily as long as they fulfill the contract that the business logic depends on.
The idea behind this concept is relatively simple: build a software architecture divided into independent layers in order to isolate the different concerns. By doing this, you can easily test your components and add or remove modules to your code because each layer is independent. Thus, you will also know exactly where to apply changes in your code, which is very appreciated when fixing bugs or updating use cases.
Using the clean architecture, changing a database, a network provider for an API, or even a UI library should be possible by only modifying a few already-known files. Thanks to dependency inversion and composition over inheritance, adding or removing frameworks is also really simple because we are working on abstractions and not on concrete classes directly.
Pros & Cons of Clean Architecture
Pros of Clean Architecture:
- Separation of concerns: Clean Architecture promotes the separation of concerns in software design, which means that different parts of the application are decoupled and have their own specific responsibilities. This makes it easier to understand and maintain the code, as well as to make changes without affecting the rest of the system.
- Testability: Clean Architecture emphasizes the importance of testing, and encourages the use of automated tests to ensure that the application is working as intended. This makes it easier to catch and fix bugs before we deploy the application.
- Reusability: Clean Architecture promotes the use of reusable components, which we can easily share and use in different parts of the application. This reduces the need for duplication of code and makes it easier to maintain and evolve the application over time.
- Modularity: Clean Architecture encourages the use of modular design, which means that the application is divided into smaller, independent components that can be easily replaced or modified without affecting the rest of the system.
Cons of Clean Architecture:
- Complexity: Clean Architecture can be complex to understand and implement, especially for developers who are new to the concept. It requires a clear understanding of the different layers and components in the system, and their respective responsibilities.
- Additional overhead: The use of multiple layers and components in Clean Architecture can add additional overhead to the development process, as it requires more time and effort to design and implement the different parts of the system.
- Limited flexibility: Clean Architecture can be inflexible in certain situations, as it requires a strict separation of concerns and a clear separation of responsibilities between different components. This can make it difficult to adapt the system to changing requirements or new scenarios.
- Limited scalability: Clean Architecture can be challenging to scale, as it requires a significant amount of upfront design and planning to ensure that the different components are correctly separated and modularized. This can make it difficult to quickly add new features or functionality to the system.
Most of the time you would not need it. Being clean requires a lot of abstractions and boilerplate code to write all those contracts between the layers. I have used it in android app, but the codebase grew a lot. It was easily maintainable due to being clean, but I was the sole developer and opted out for a simpler MVP architecture. I think it’s great if you’re writing a business application that should be maintainable for a decade or so with various developers. It’s the safest bet. But for a simpler app, it’s overkill.
Clean Architecture
The concept of Clean Architecture was defined by Robert C. Martin in his book titled “Clean Architecture: A Craftsman’s Guide to Software Structure and Design”. In this architecture, systems can be divided into two main elements: the policies and the details. The policies are the business rules and procedures, and the details are the items necessary to carry out the policies. It is from this division that Clean Architecture begins to differentiate itself from other architectural patterns. The architect must create a way for the system to recognize the policies as the main elements of the system, and the details as irrelevant to the policies.
In the clean architecture, it is not necessary to choose the database or framework at the beginning of the development, as all these are details that do not interfere with the policies and, consequently, can be changed over time.
Layer Division
In Clean Architecture there is a well-defined division of layers. The architecture is framework-independent, i.e., the internal layers that contain the business rules do not depend on any third-party library, which allows the developer to use a framework as a tool and not adapt the system to meet the specifications of a particular technology. Other benefits of Clean Architecture are: testability, UI independence, database independence and independence from any external agents (business rules should not know anything about the interfaces of the external world).
To illustrate all these concepts, the diagram shown in the figure below was created.
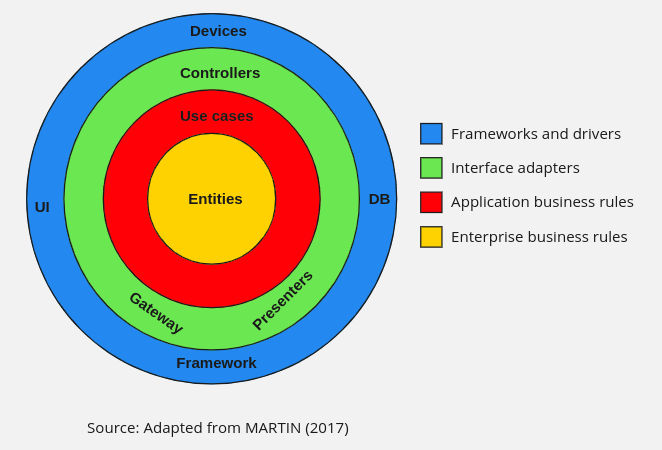
Each layer in the figure represents a different area of the software, the innermost part being the policies and the outermost the mechanisms.
The main rule for Clean Architecture is the Dependency Rule, which says that the dependencies of a source code can only point inwards, that is, in the direction of the highest level policies. That said, we can say that elements of an innermost layer cannot have any information about elements of an outermost layer. Classes, functions, variables, data format, or any entity declared in an outer layer must not be mentioned by the code of an inner layer.
Application business Layer
The innermost layer is the Entities layer, which contains the application’s business objectives, containing the most general and highest level rules. An entity can be a set of data structures and functions or an object with methods, as long as that entity can be used by multiple applications. This layer must not be altered by changes in the outermost layers, that is, no operational changes in any application should influence this layer.
The use case layer contains the application-specific business rules, grouping and implementing all the use cases of the system. Use cases organize the flow of data to and from entities and guide entities in applying crucial business rules to achieve use case goals. This layer should also not be affected by the outermost layers, and your changes should not affect the entities layer. However, if the details of a use case change, some of the code in that layer will be affected.
The interface adapters layer has a set of adapters that convert the data to the most convenient format for the layers around it. In other words, it takes data from a database, for example, and converts it to the most convenient format for the entity layers and use cases. The reverse path of conversion can also be done, from the data from the innermost layers to the outermost layers. Presenters, views, and controllers belong to this layer.
Framework and Database Layer
The outermost layer of the diagram is usually made up of frameworks and databases. This layer contains the code that establishes communication with the interface adapters layer. All the details are in this layer, the web is a detail, the database is a detail. All these elements are located in the outermost layer to avoid the risk of interfering with the others.
But if the layers are so independent, how do they communicate? This contradiction is resolved with the Dependency Inversion Principle. Robert C. MARTIN explains that you can organize the interfaces and inheritance relationships so that the source code dependencies are opposite the control flow at the right points.
If a use case needs to communicate with the presenter, this call cannot be straightforward as it would violate the Dependency Rule, so the use case calls an interface from the inner layer and the presenter in the outer circle does the implementation. This technique can be used between all layers of the architecture. The data that travels between the layers can be basic structures or simple data transfer objects, these data being just arguments for function calls. Entities or records from the databases must not be transmitted in order not to violate the Dependency Rule.
Clean Architecture is an architectural pattern that aims to create a separation of concerns between the various components of a software system. It is based on the idea that the structure of a system should follow the dependencies of its components, with the most stable and independent components being at the center, and the most volatile and dependent components being at the outer layers.
CQRS and MediatR pattern
The Command and Query Responsibility Segregation (CQRS) pattern is an architectural pattern that separates the responsibilities of reading and writing data within a system. It is based on the idea that the data read by a system should be separate from the data written by the system, and that the two should be optimized for their respective tasks.
The MediaTR pattern is an architectural pattern that separates the concerns of reading and writing data within a system by using different database technologies for each task. It is based on the idea that the database technology used for reading data should be optimized for that task, and that the database technology used for writing data should be optimized for that task.
Onion Architecture is an architectural pattern that aims to create a separation of concerns between the various components of a software system. It is based on the idea that the structure of a system should follow the dependencies of its components, with the most stable and independent components being at the center, and the most volatile and dependent components being at the outer layers.
Domain Driven Design
Domain Driven Design (DDD) is an approach to software development that focuses on modeling the business domain of a system. It is based on the idea that the structure of a system should follow the structure of the business domain it represents, and that the various components of the system should be designed to support the business needs of the domain.
Command Query Segregation (CQS) is a principle that states that every method in a software system should either be a command that performs an action or a query that returns data, but not both. In other words, a method should either modify the state of the system or return information about the state, but not both.
This principle is closely related to the Single Responsibility Principle, which states that a class or module should have only one reason to change. By following CQS, we can ensure that our classes and modules have a single, well-defined responsibility, which makes them easier to understand and maintain.
One of the benefits of following CQS is that it can help us design more maintainable and scalable software systems. By separating commands and queries, we can more easily reason about the different parts of our system and how they interact with each other. This makes it easier to change or extend our system without introducing unintended side effects.
Conclusions
There is no architecture that is the “silver bullet” and can solve all problems. And it’s not Clean Architecture that came to this.
Once the application base has been created, Clean Architecture helps to maintain and evolve the application without requiring much cost (either physical or time). This help is provided by the fact that its layers are independent and by the constant use of design patterns. Thus, changes to a certain part of the system tend not to interfere with the operation of the rest of the application.
On the other hand, a more experienced team of developers is needed to work on the system. It takes knowledge of design patterns to be able to maintain and structure the software. It also takes longer than a simple MVP application to see the first results, so it’s important to have strong client alignment to make the future benefits clear.
Finally, it is concluded that for applications that tend to grow and remain for many years, the Clean Architecture approach is a good solution to use. However, for simple and non-evolving systems, it may not be worth the effort with such an architecture, being wiser to follow simpler architectural patterns.